Numerai & ML - Part 2 - First models: Random Forests, Support Vector Machine, Logistic Regression, Gradient Boosting, Deep Neural Network
Looking for inspiration I came across the Tech in Pink blog where the author is giving a couple of examples.
In two posts the author demonstrates how to apply to this task the following learning methods: random forests, random forests with hyper-parameter grid search and support vector machine.
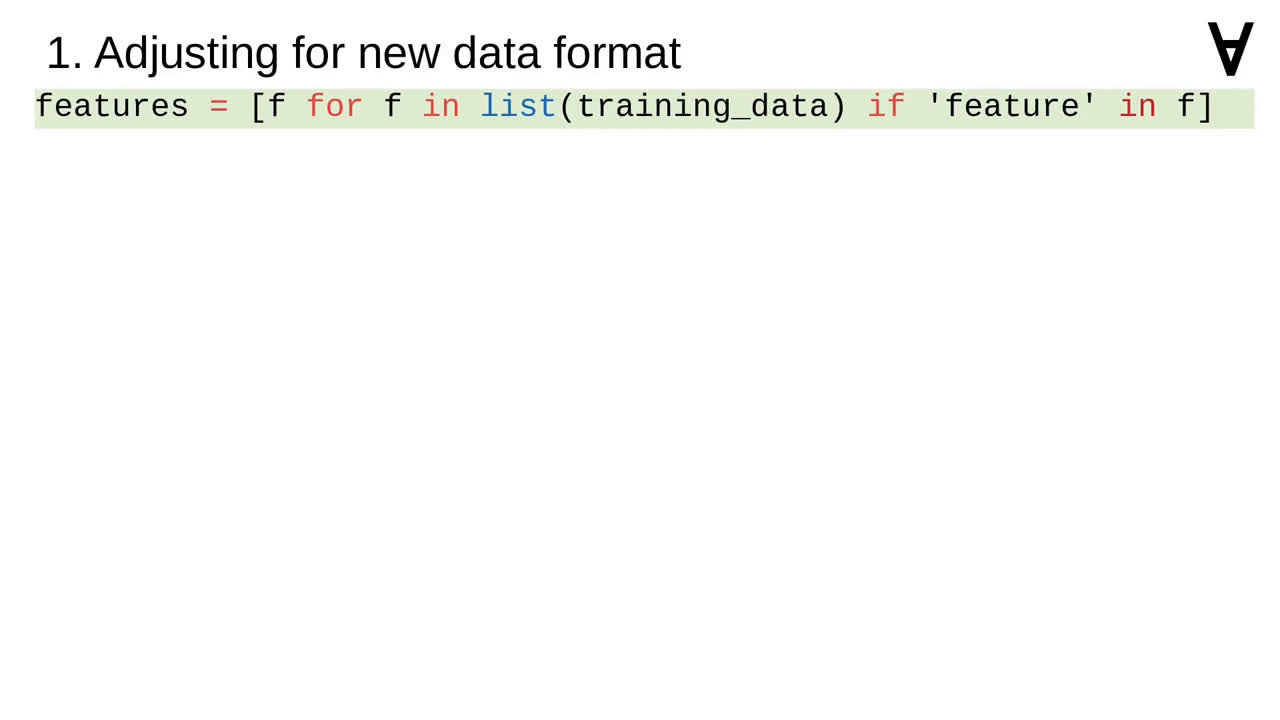
Since the time of publishing the format of the data changed to the one shown here. Therefore, I had to modify the code.
I added the code to extract the names of the feature columns.
The list of feature columns had to be applied to extracting of feature values from training data.
The name of the ID column also needed to be changed.
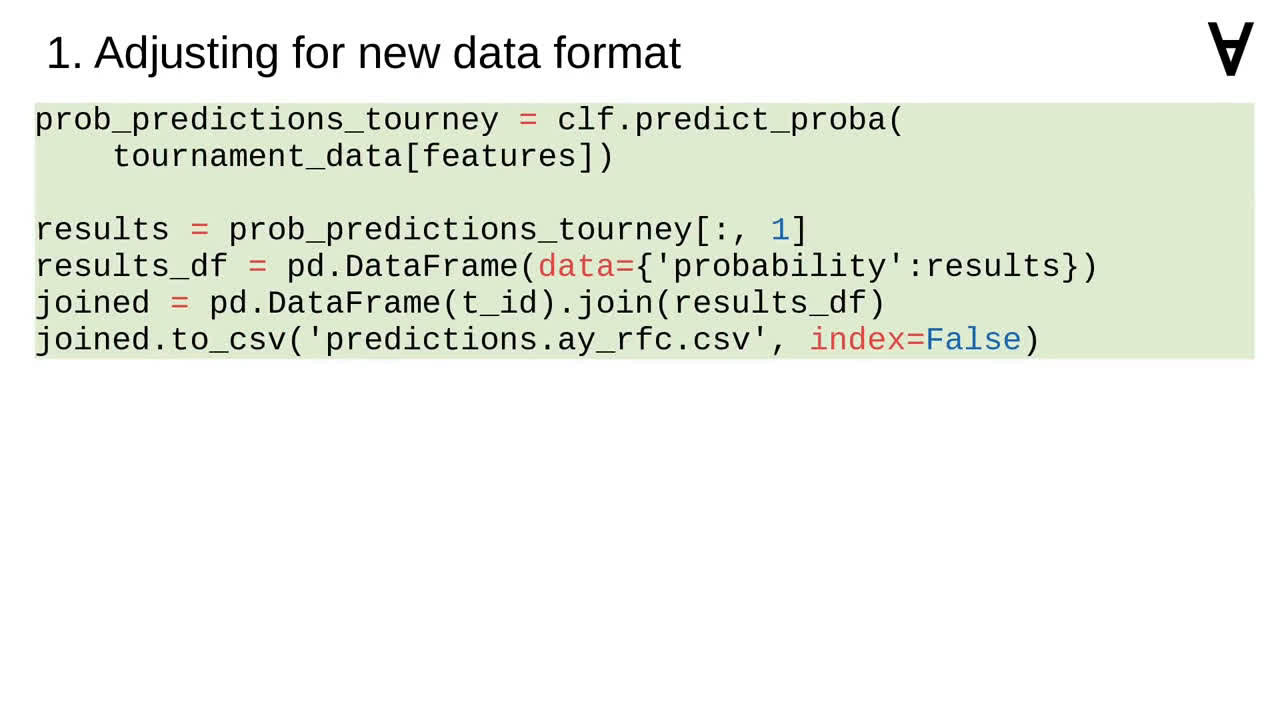
And the list of feature columns had to be applied to the prediction code as well.
Storing the predictions to disk also did not match the currently required format.
Thus, this had to be adjusted as well.
As it turns out, the submission process may fail if the probability is equal to 0 or 1.
Therefore, it was necessary to find out the granularity of the floating-point type.
...and clip the probabilities to an open interval from 0 to 1.
The code also raised a few deprecation warnings. In particular, the cross validation and grid search were moved to the model selection module.
There was also some obsolete Python 2 code which needed to be updated to Python 3.
To gain some flexibility I decided to replace the hard-coded file names by parameters obtained from environment variables...
...and to introduce a main script called run.py which allows me to select the learning method.
For some of the learning methods it is possible to use all CPU cores and in scikit-learn this can be enabled by setting n_jobs to -1.
It is not possible though for support vector machine classification.
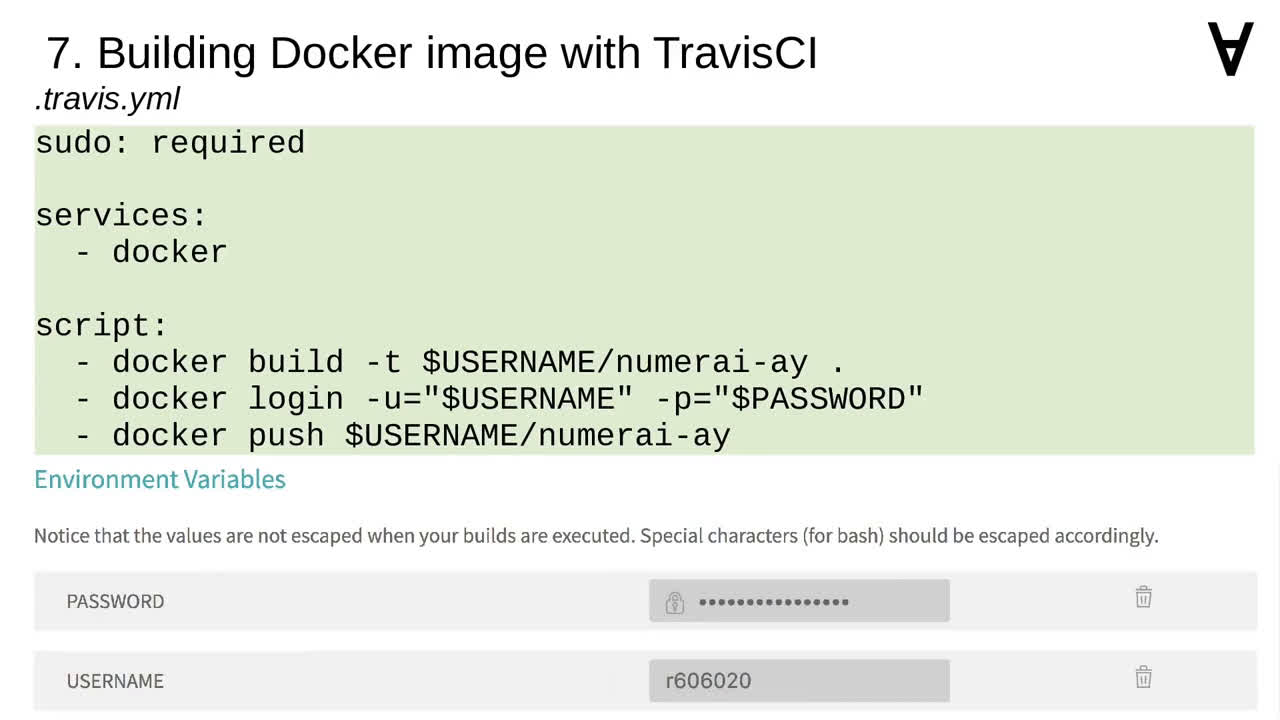
To keep the code clean I decided to wrap the code in a Docker container. Therefore, I needed to prepare requirements.txt file with all the necessary modules...
...including NumPy and SciPy modules...

...Pandas module...