Numerai & ML - Part 3 - Automatic ML: auto-sklearn & Auto-WEKA
In previous two parts I showed examples where a particular model is trained and then applied to generate predictions. One decision to make was which learning method to use.
For example, a logistic regression...
...or a deep neural network...
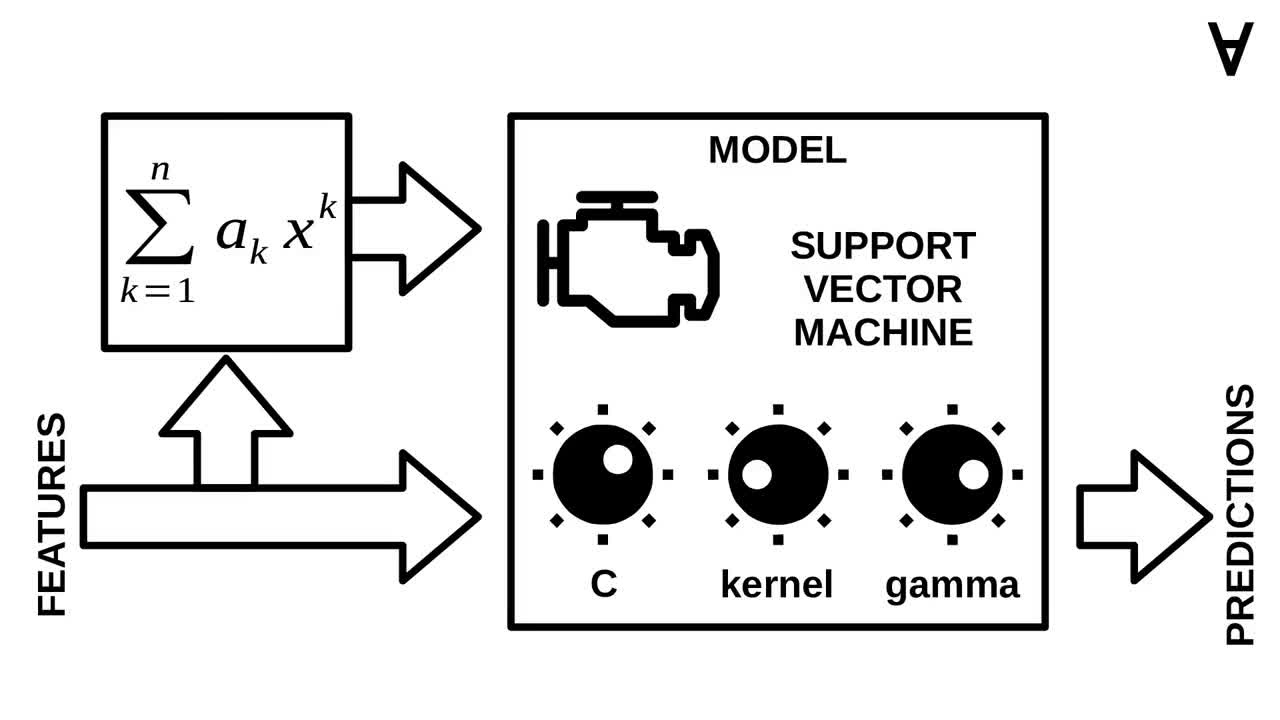
...or a support vector machine.
Another decision was which values of the hyper-parameters to use (and I used grid search to automate it).
Yet another decision was related the application of feature engineering...
...which could be feature scaling or normalization...
...or calculating polynomials of the input features or application of other functions.
But what if all that could be automated? Turns out there are frameworks which do just that. One such framework is Python-based auto-sklearn.
Because it automates application of scikit-learn we can start with the familiar code reading the training and tournament data...
...then extract the names of the feature columns...
...and read the training feature values, corresponding target class values, tournament feature values and their identifiers.
Once that's done, we can create a meta-model and fit it to the training data.
Then we can use it to make the prediction...
...remembering to clip the probabilities to an open interval from 0 to 1...
...and store them together with the record identifiers.
Like in previous cases I prepared requirements files. One with the modules auto-sklearn depends on...
...and another one with auto-sklearn.
I also created the Dockerfile which uses Python 3 base image.
Then, it installs libraries necessary for algebraic computation and other purposes.
It also installs the Python modules listed earlier.
...as well as the Python script to be called when the container is executed.
Assuming the Docker is installed and you are in the directory which contains a Numerai dataset you can run the code like this.
There are more frameworks automating application of machine learning. Auto-WEKA is an another example (this time - Java-based).
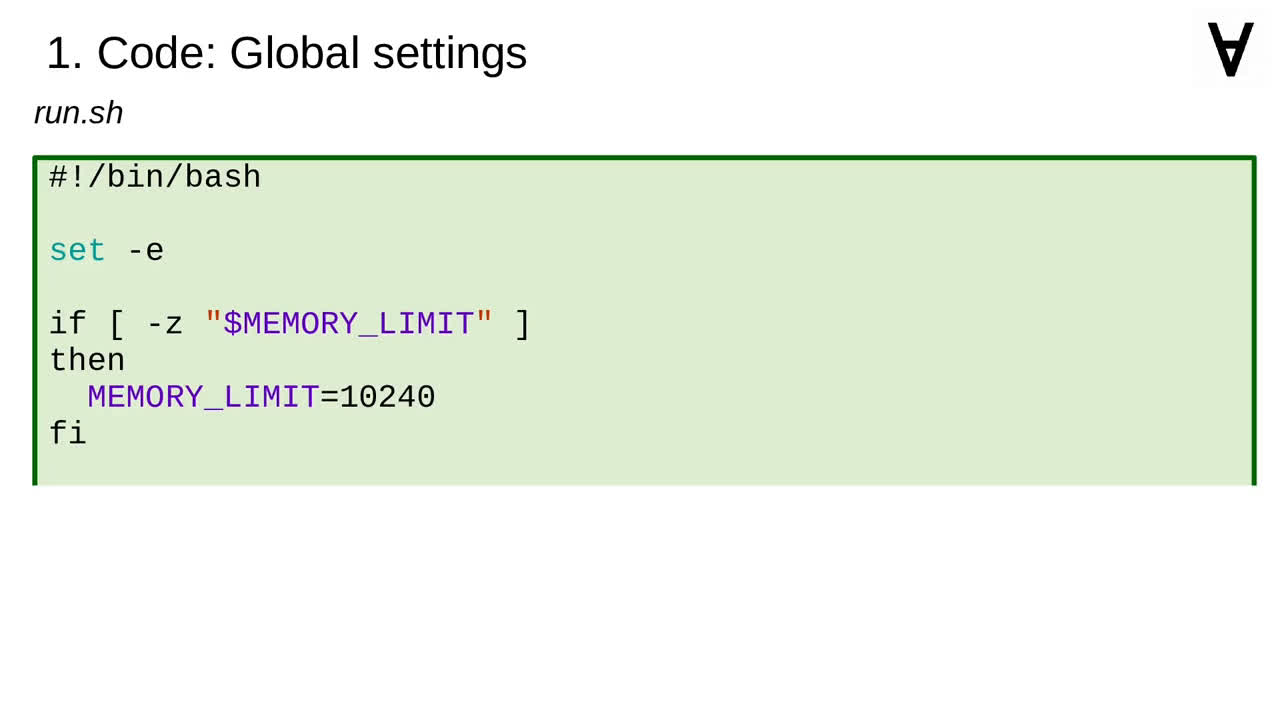
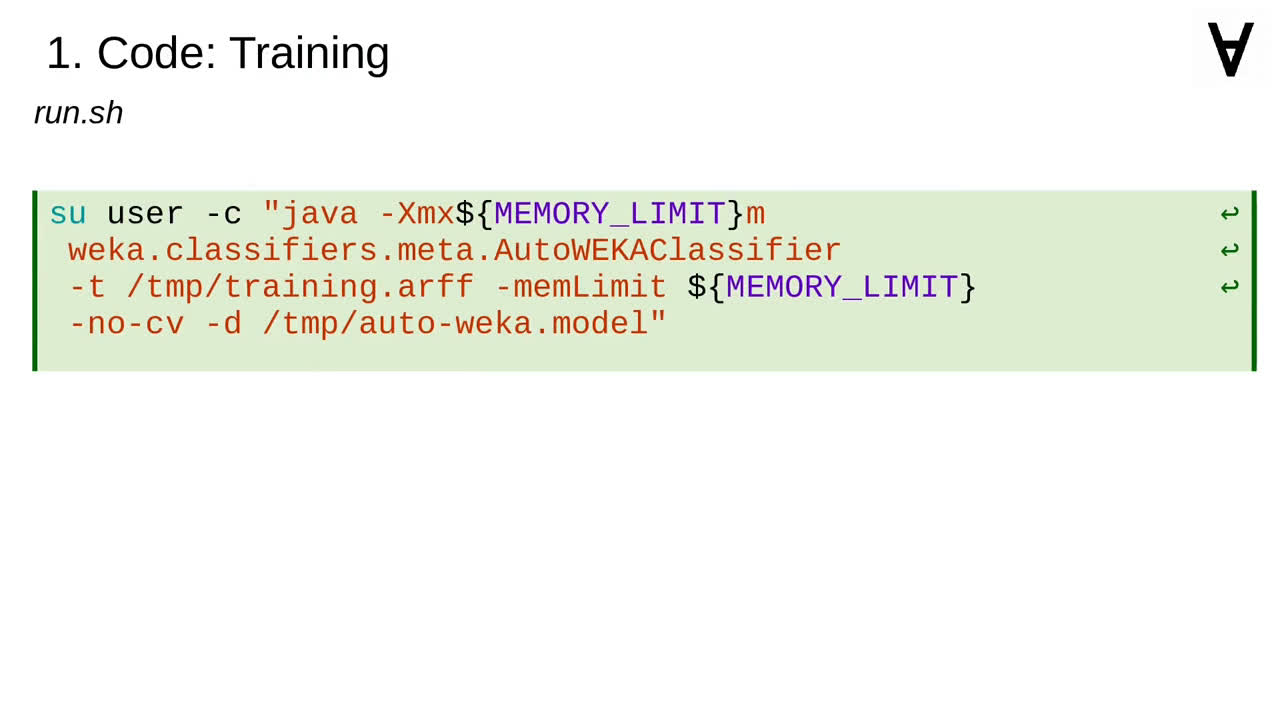
Fortunately, it is possible to use it from the command line so I will create a script (which will exit immediately in case of a failure).
I noticed that the framework requires at least 10GB of memory to work on Numerai data.
The framework works with the ARFF format so it is necessary to convert the training data. Let's start by counting the number of rows.
Then, we convert all of the rows of the CSV file to the ARFF file...
...and we remove first three columns to leave only the feature and the target values.
We also rename the "target" column name to "class" and declare it to have only two values - 0 or 1.
In a similar way we also convert the tournament data file.
Once the data is ready we train and store the model...
...and apply it to generate the predictions which are then stored in a "raw" output file.
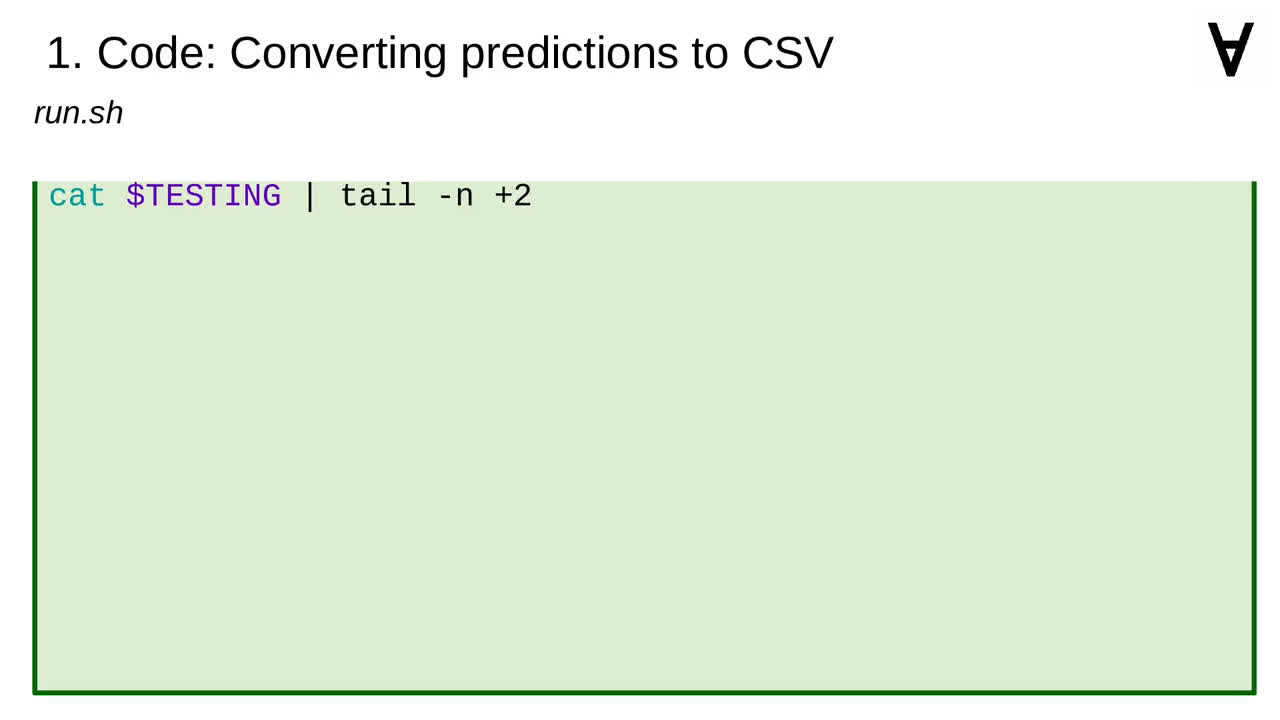
To convert the predictions to a format accepted by Numerai let's list the original tournament data...
...skip the first line which contains the names of the columns...
...grab only the first column with the identifiers and store them in a separate file.
Then, let's list the raw output file...
...skip the empty lines...
...and first two lines with the header...
...split the remaining output with the ":" delimiter and use only the third column...
...then drop the "+" indicator...
...use the prediction probability column if the prediction is 1 (or its complement if the prediction is 0)...
...and after clipping the probabilities to an open interval from 0 to 1 store them in a separate file.
Now, the only thing we need is to create the submission file with the right header...
...and then join the files with the identifiers and the probability values and append the result to the submission file.
The Docker file is going to be based on Ubuntu LTE image...
...with addition of build tools, Java, curl, unzip and libraries for arithmetic calculations...
...we need to create a user to avoid the issues of running the framework as root...
...then we need to download and install WEKA...
...and the Auto-WEKA package.
Finally, we need to copy the shell script and call it as root when the container is executed.
Here is the command to run that container. Note that the container image name is different in this case.
So what was the score for each of these two? In both cases the predictions met two criteria with a rather low log loss values. Unfortunately, that's still not good enough to qualify.